0x00 背景介绍
拜占庭将军问题
拜占庭帝国,即5-15世纪的东罗马帝国,当时帝国中有许多支军队,每支军队都由一位将军独立指挥,这些军队都驻扎在敌军城外,将军们必须达成统一的意见才能决定是否进攻,也就是说每位将军都会收到其他所有将军的指令,如果所有人收到的指令都一样才算成功,否则就算失败,这就是拜占庭将军问题。允许一小部分不一样的指令存在也算成功的称之为拜占庭容错问题。
拜占庭容错机制的一个明显的优势就是可以提升软件的可用性,我们知道程序不可能绝对没有Bug,软件在实际运行过程中总会出现各种错误,可能由于内部错误,也可能由于外部的攻击,例如DOS等。而拜占庭容错机制采取的方法则是为软件增加多个副本,当其中某些副本出现问题时仍然能保证软件提供正常的功能。
0x01 系统模型
首先,由于这篇论文介绍的是一个协议,所以必须要规定协议的运行环境以及一些条件假设,这也是所有介绍协议的论文必须的一部分,官网的术语就称为系统模型。
本文假设一个分布式系统,所有节点都在同一个网络中,网络可能会拒绝,延迟,重复或者乱序传送消息。节点出错的可能性是相互独立的,也就是说节点出错是由随机因素造成的,而不是统一的错误造成所有节点错误。文章在介绍这一部分时原文如下
为了保证每个节点出错是相互独立的,所有的节点都应该运行不同的实现代码并且保证提供相同的功能,已经操作系统的root密码应该也各不相同,并且管理员也都不相同。不同的实现版本可以采用N-Version Programming或者请不同的程序员来实现。
先不从功能上来说,光这假设条件就太严格了,而且即使使用了上述的方法也无法保证代码不会出现统一的错误,只是减少了可能性,将错误进行了随机分布。所以这个假设条件可以说是多余的。
最后假设敌手的能力,敌手可以操控错误的节点,可以延迟包括正确节点的通信,但是不能无限的延迟,敌手无法攻破使用的密码学算法。
0x02 算法属性
该算法可以用于实现任何确定的带有状态和操作的replicated service(复制服务???),操作除了简单的读写之外,还可以包括任何确定的计算。客户端可以向replicated service发起请求并阻塞等待回复。
在错误节点(即被攻击者所控制)不超过$\lfloor\frac{n-1}{3}\rfloor$时,该算法可以提供Safety和Liveness两个属性。Safety在原文中的解释是
Safety是说replicated service满足线性一致性(linearizability),就像中心化的实现一样每次执行一个操作。Safety要求错误副本的数量有一个上限,因为错误的副本可能会执行任意操作,导致错误的结果。
这也是整篇文章出现的一个问题,总是用很抽象的文字来描述另一个抽象的概念,所以让人看完之后就跟没看一样,有时甚至觉得模棱两可还不如不说。我对Safety的解释是当有多个客户端同时访问服务的时候,他们请求的操作不会相互干扰,执行的结果就像单独轮流执行一样,都会返回正确的结果。
Safety是不依赖于同步性的,但是Liveness则必须要依赖同步性。Liveness的意思是说客户端最终都会收到回复,如果错误副本不超过$\lfloor\frac{n-1}{3}\rfloor$并且delay(t)不会无限增长快于t,这里delay(t) = 消息最终被接受的时间 - 消息首次(可能会多次重发)发送时间t。
错误的副本无可避免的要泄露一些信息给攻击者,因为副本要使用这些信息进行后续的计算。但是可以考虑使用安全多方计算来进行隐私保护。
0x03 算法流程
算法是以复制状态机的形式运行的,服务(上文的replicated service)用状态机来进行建模,并且复制到分布式系统中不同的节点上。每一个副本都维护一个服务状态,并且通过相应的操作转移到下一个状态,所以副本都必须始于统一状态,并且当操作及参数相同时下一个状态也是确定的。我们用$\cal{R}$来表示副本的集合,每一个副本用一个整数${0,1,…,{\cal{R}}-1}$来表示,并且我们假设${\cal{R}} = 3f + 1$,$f$是最多可能出错的节点数。副本通过不同的配置不断进行变化,每一个版本的副本我们称之为view。在每一个view中,其中一个节点称为primary,其它节点是backups,Views是连续进行标号的,并且在一个确定的view中primary的副本序号$ p = v\,\,mod\,\,{\cal{R}},v$是当前的view序号,只有当primary崩溃时才会进行view的改变。算法整个的工作流程如下
- 客户端给primary发送一个请求,调用相应的服务操作。
- primary将请求组播给所有的backups。
- 所有的副本执行请求,并给客户端发送执行结果。
- 客户端等到从不同的副本收到$f+1$个相同的结果,就将这个相同的结果作为最终的结果。
客户端操作
客户端通过发送一个$<REQUEST,o,t,c>_{\sigma_c}$消息给primary来请求执行操作$o$,t是对应的时间戳,然后primary收到客户端的请求后,组播给所有的backups,最后所有的副本执行完操作之后将结果通过消息$<REPLY,v,t,c,i,r>$返回给$c$,$r$表示执行的结果。
一般情况协议执行流程
一般情况也就是当primary正常工作的情况下,协议主要分为三个阶段分别是pre-prepare,prepare和commit阶段,如下图所示。
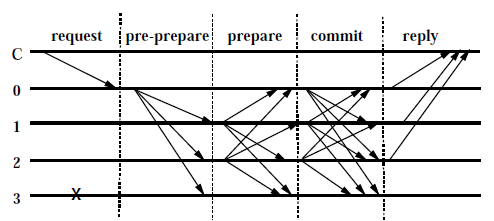
1 pre-prepare
当primary收到客户端的请求之后,给请求按顺序依次分配序列号(因为可能同时收到多个请求),这是为了让所有的副本都按照统一的顺序来执行请求的操作。然后primary组播一个pre-prepare消息$ < <PRE-PREPARE,v,n,d>_{\sigma_p},m>$给所有的backups,这里v表示当前的view,通过这个view来确定当前的primary;n表示primary给消息m分配的序列号;d表示m的摘要(哈希值),防止m被篡改,并且primary只在pre-prepare消息中将m的明文传输给所有的backups,backups会将m保存起来,之后的消息中都只传输m的摘要来减少网络传输量。backups通过验证以下几个条件来决定是否接受pre-prepare消息
- 签名和摘要是否正确
- v是否是当前的view
- 之前有没有接收过相同n和d的请求
- n是否位于[h,H]间,这是为了避免坏的primary随意分配序列号造成空间不足
2 prepare
当backup接受pre-prepare消息后,就进入prepare阶段。为什么需要这个阶段呢?如果primary是恶意的,那么它有可能对同一个消息分配不同的序列号然后再分别发送给不同的backups,那么对于每个backup来说序列号都是正确的,但是实际上backups执行请求的顺序还是不一致的。所以prepare阶段的目的就是backups间彼此确认由primary分配的序列号是否正确(对于同一个消息是否分配了唯一的序列号)。这是通过组播一个$<PREPARE,v,n,d,i>_{\sigma_i}$消息给所有的副本,当其他副本收到prepare消息之后,确认相应的信息是否正确。当副本i发送完PREPARE消息之后就把pre-prepare消息和prepare消息都插入到日志中。
这里还需要定义一个谓词$prepared(m,v,n,i)$,当副本i向日志中插入了m,和m对应的一个pre-prepare消息以及和pre-prepare对应的$2f$个prepare消息时,$prepared(m,v,n,i)$为真。
3 commit
当副本i的谓词$prepared(m,v,n,i)$为真时,该副本就进入commit阶段。同样为什么需要这个阶段呢?这里引用网上一个大牛的解释
设想一下,在t1时刻只有replica 1把请求m(编号为n)带到了prepared状态,其他两个备份节点replica 2, replica 3还没有来得及收集完来自其它节点的PREPARE信息进行判断,那么这时发生了view change进入到了一个新的view中,replica 1还认为给m分配的编号n已经得到了一个quorum同意,可以继续納入序列中,或者可以执行了,但对于replica 2来说,它来到了新的view中,它失去了对请求m的判断,甚至在上个view中它还有收集全其他节点发出的PREPARE信息,所以对于replica 2来说,给请求m分配的编号n将不作数,同理replica 3也是。那么replica 1一个人认为作数不足以让全网都认同,所以再新的view中,请求m的编号n将作废,需要重新发起提案。所以就有了下面的commit阶段。
在简略解释下就是一个副本进入prepared状态(谓词$prepared(m,v,n,i)$为真),它无法确定其他人是否也进入了prepared状态,如果此时进行了view change而没有后面的commit过程,就会造成最终副本状态不一致的情况。所以添加了commit阶段,这个阶段的目的是保证即使在进行view change时,所有的请求依然具有全局统一的顺序。
进入commit阶段后,副本组播一个$<COMMIT,v,n,D(m),i>_{\sigma_i}$给其他所有副本,其他副本收到消息后确认消息的正确性。当副本收到$2f+1$个commit消息之后,就可以确认所有非恶意副本执行请求的顺序是一致的了,此时就可以执行请求然后返回结果给客户端了。
Garbage Collection
对于上面的协议,给人的一个直观的感觉就是传输的消息太多了,而如果一直保存所有的通信消息,对于系统而言也是一个极大的负担。所以协议设定了定期清理过期的消息,之所以不立即清理的原因是之前存储的消息之后还有可能会用到。所以协议设定每隔一个常数时间(可以自己设定,如100等,称之为checkpoint)清理一次,在清理之前还要做一个确认工作,通过组播一个$<CHECKPOINT,n,d,i>_{\sigma_i}$;n是最后一个执行的请求的序列号;d是当前状态的摘要;当副本收到$2f+1$个不同副本发来的带有相同n和d的checkpoint消息是,就可以称当前状态是稳定的了,也就是可以清除所有序列号小于等于n的消息了。而收到的$2f+1$个checkpoint消息就作为n是稳定的证据。
View change
Backup在收到一个有效的请求时就会启动一个timer,当请求执行完之后就停止timer,如果在请求执行完之前timer已经超时了,那么backup就怀疑当前的primary是坏的,从而组播一个\(<VIEW-CHANGE,v+1,n,C,P,i>_{\sigma_i}\)消息给其他所有副本当View v+1中的primary收到2f+1个view-change消息,新的primary就组播一个\(<NEW-VIEW,v+1,V,O>_{\sigma_p}\)消息,其中关于$O$的计算方法请参见论文。其他副本收到new-view消息之后,解析出$O$中的消息,依然按照原来的协议继续(从prepare开始)执行。
0x04 总结
原本论文笔记是打算写给自己看的,可是写着写着发现是写给不懂的人看的了,一篇论文看了个把星期,效率是有点低,主要的时间都费在想[为什么要这一步?]上了,论文本身不难懂,但科研毕竟是科研,不像工程知道怎么做就行了,这里的每一步都需要想想为什么这么做?不这么做会怎么样?算是第一篇论文笔记了,费了些时间,就当开了个好头,以后可能专门就写给自己看了,写个关键部分,肯定不会这么详细了。